
Deep learning is a machine learning method consisting of multiple layers that predict results with a given data set. Deep learning, machine learning, and artificial intelligence are terms that have different meanings. Deep learning can be summarized as a sub-branch of machine learning, while machine learning is a sub-branch of artificial intelligence.
Keras uses Tensorflow for its backend. Keras is one of the most important packages in deep learning. Actually, Keras is not a deep learning library per se. Keras offers you a high-level API (application programming interface) where you can use Google Tensorflow, Microsoft CNTK, and Theano deep learning libraries. In this way, it is possible to train the deep learning architecture you have created using different packages.

Each project can have its own dependencies, so we should use a virtual environment. With this method, you avoid conflicting requirements by creating different virtual environments for your different applications.
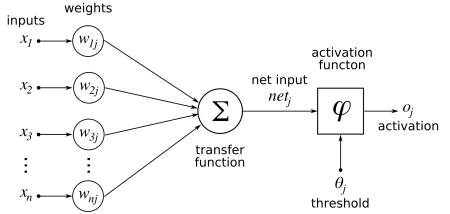
Dendrites receive messages from other neurons and Axon transmits signals to other neurons.
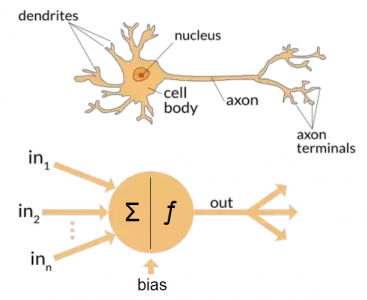
Each circle in a neural network is a Neuron/Node.
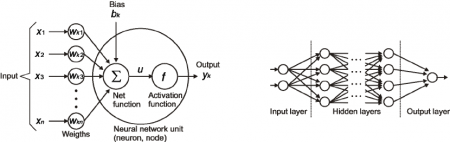
Hidden layers are the layers where the computations appear. If a neural network has 10 layers in total, 8 of them are hidden layers.
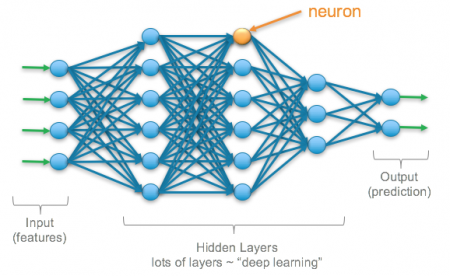
A neural network is called a deep neural network if it contains 2 or more hidden layers.
Each neuron has a function inside.
The modern activations functions do the non-linear transformation to the input making it capable to learn better.
Non-Linear activations function allow backpropagation and allow multiple hidden layers.
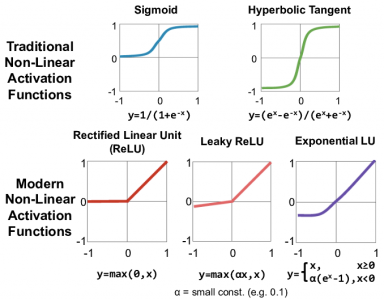
Non-linear Activation Functions:
*Relu ( it outputs 0 if the input is negative)
*Sigmoid (Logistic) (Sigmoid functions outputs a value between 0 and 1)
*Softmax (it is able to handle multiple classes and is useful for the output neurons)
*Leaky Relu
*TanH or Hyperbolic Tangent (TanH is very similar to Sigmoid)
The objective of a Deep Learning model is to minimize the cost function.
We can use MSE (mean squared error) for the regression problems.
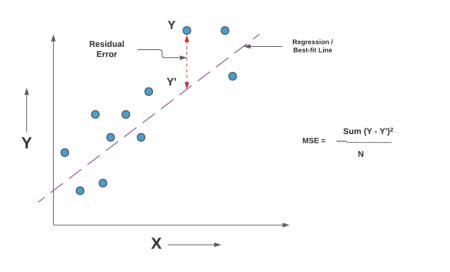
Cost function decreases as the model learns.
Gradient descent is an optimization algorithm used to minimize the cost function.
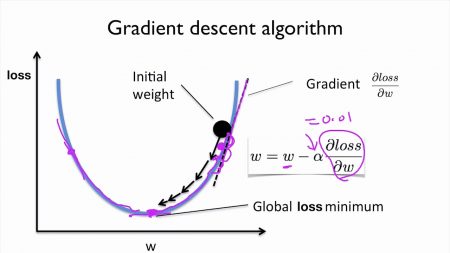
The model optimizes the weights and biases to minimize the cost function.
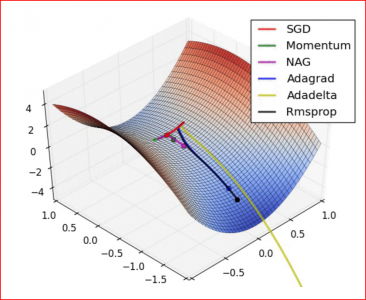
Adam, AdaGrad, RMSProp are the optimization algorithms.
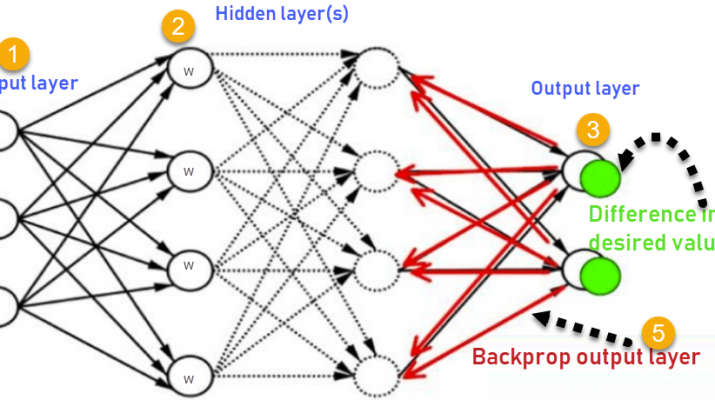
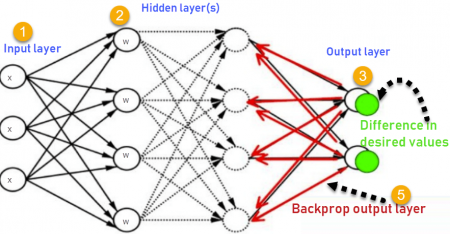
The model moves backward through a network to update the weights and biases. This whole process is called Backpropagation.
One epoch means, the entire dataset is passed forward and backward through the neural network once. Batch size refers to the number of training examples utilized on one iteration.



