
The complexity of modern software systems is increasing, and the resulting software applications often contain defects that can have severe negative impacts on the reliability and robustness of these applications.
A software defect is commonly defined as a deviation from the software specifications or requirements. Such defects might lead to failures or produce unexpected results. To reduce failures and improve software quality, many software quality assurance activities (e.g., defect prediction, code review and unit testing) are employed. Such activities typically cost approximately 80% of the total budget of a project. To minimize the cost, software engineers want to know which software modules contain more defects and inspect such modules first. As a result, software defect prediction techniques have been proposed.
Software defect prediction techniques help identify software system modules that are more likely to contain defects. Defect prediction techniques can be used to build models that rank software modules by the predicted number of defects, defect probability, or classification results. This ranked list can reflect the priority for code inspection or unit testing and can thus be used to determine the order in which code should be inspected. Consequently, the developers can allocate the limited test resources to the code areas most likely to contain bugs. The resulting savings in labor and time costs can reduce the overall cost of maintenance activities and maximize company profits.

Abstract
Software systems have become larger and more complex than ever. Such characteristics make it very challengeable to prevent software defects. Therefore, automatically predicting the number of defects in software modules is necessary and may help developers efficiently to allocate limited resources. Various approaches have been proposed to identify and fix such defects at minimal cost. However, the performance of these approaches require significant improvement.
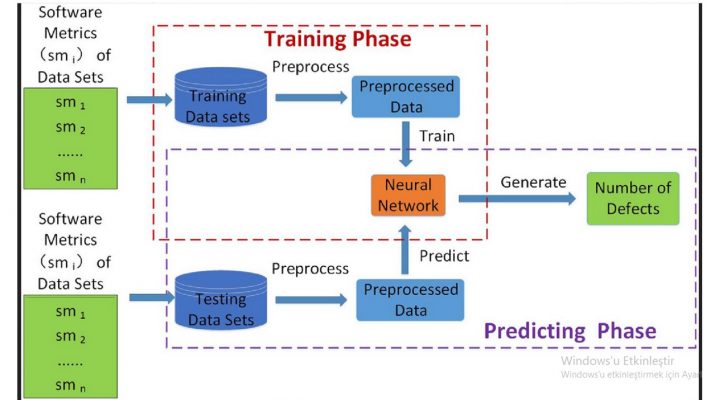
Therefore, in this paper, we propose a novel approach that leverages deep learning techniques to predict the number of defects in software systems. First, we preprocess a publicly available dataset, including log transformation and data normalization. Second, we perform data modeling to prepare the data input for the deep learning model. Third, we pass the modeled data to a specially designed deep neural network-based model to predict the number of defects. We also evaluate the proposed approach on two well-known datasets. The evaluation results illustrate that the proposed approach is accurate and can improve upon the state-of-the-art approaches. On average, the proposed method significantly reduces the mean square error by more than 14% and increases the squared correlation coefficient by more than 8%.
Lei Qiao
Xuesong Li
Qasim Umer
Ping Guo


